LLM Wiki für Deutsch – Ein Obsidian-Plugin, das meine Notizen zum Leben erweckt
Seit einiger Zeit sammle ich Wissen in Obsidian. Unterrichtsmaterialien, Ideen für den Physikunterricht, Notizen zu Robotik-Projekten, Schul-IT, Büchern, etc – alles brav verlinkt, aber irgendwie doch schwer durchsuchbar. Dann stieß ich auf LLM Wiki, ein Plugin, das Andrej Karpathys Idee von LLM Knowledge Bases umsetzt. Dabei geht es darum, mit einem LLM eine persönliche, durchsuchbare Wissensbasis aus den eigenen Notizen zu bauen. Dieses Plugin klang vielversprechend und entsprach dem, was ich gesucht habe – aber es gab einen Haken: Deutsch.
Was das Plugin macht
LLM Wiki liest den gesamten Vault, schickt jede Notiz an ein lokales Sprachmodell und extrahiert daraus strukturiertes Wissen: Entitäten (Personen, Tools, Projekte, Bücher…), Konzepte und die Verbindungen zwischen ihnen. Alles landet in einer knowledgebase.json-Datei, und für jede Entität wird eine eigene Markdown-Seite generiert – kompatibel mit Obsidians Bases. Fragen stellt man dann in natürlicher Sprache, das Plugin sucht den passenden Kontext heraus und schickt ihn zusammen mit der Frage ans Modell.
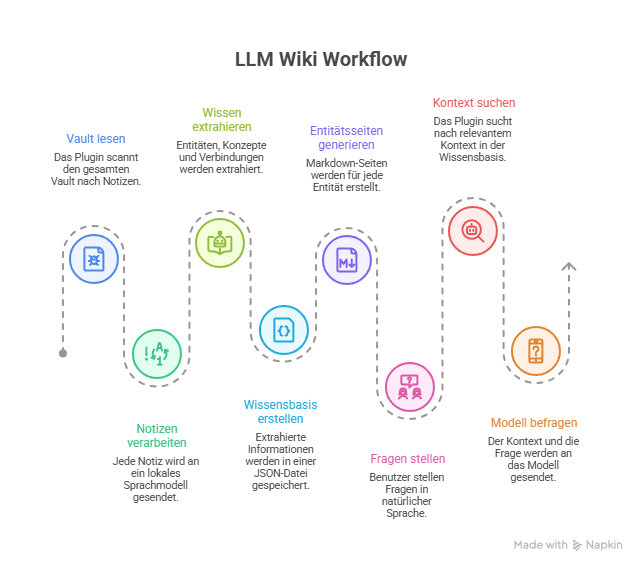 )
)
Das Ganze läuft per Default vollständig lokal: Ollama mit bei mir mistral-nemo als Chat-Modell. Das im englischen PlugIn voreingestellte nomic-embed-text für Embeddings habe ich für die deutsche Version durch qllama/multilingual-e5-large-instruct ersetzt, da es bessere Ergebnisse lieferte.
Kein Cloud-Account, keine Daten, die das eigene Gerät verlassen. So muss ich mir als Lehrer, der auch mit Schüler- und Unterrichtsdaten arbeitet, keine Sorgen bei der Verwendung von KI machen.
Warum ein Fork für Deutsch?
Das Original-Plugin wurde auf Englisch ausgelegt. Nicht nur die UI – der eigentliche Extraction-Prompt, der Herzschlag des Systems, fragte das Modell in englischen Instruktionen nach englischen Ausgaben. Für einen deutschsprachigen Vault bedeutet das: Das LLM extrahiert Entitäten und beschreibt Konzepte auf Englisch, obwohl die Quellen auf Deutsch sind. Suchen auf Deutsch finden dann nichts oder Falsches.
Ich habe deshalb llm-wiki-german als Fork gestartet – als Proof of Concept dafür, dass LLM Knowledgebases auch auf Deutsch brauchbare Ergebnisse liefern.
Gleichzeitig war es eine gute Gelegenheit, Vibe Coding mit der Gemini CLI auszuprobieren.
Die Herausforderungen mit Deutsch
Der Extraction-Prompt auf Deutsch
Der erste und wichtigste Schritt war, den Extraction-Prompt komplett auf Deutsch umzuschreiben. Im Fork ist er jetzt vollständig auf Deutsch formuliert – von den Regeln für das Modell bis zu den JSON-Beispielen. Der Prompt instruiert das Modell explizit, die Ausgabe in der konfigurierten {output_language} zu liefern, unabhängig von der Sprache des Quelltexts. So kann man auch einen gemischten Vault (z. B. mit englischen Fachartikeln und deutschen Unterrichtsnotizen) konsistent auf Deutsch oder Englisch indexieren.
Stoppwörter und Tokenisierung
Die Keyword-Suche im Original war rein auf Englisch ausgelegt. Für den deutschen Vault musste ich die Stoppwortliste in terms.ts massiv erweitern: der, die, das, ein, eine, ist, sind, von, zu, und, oder, aber, wenn… Ohne das würden diese häufigen Wörter das Ranking dominieren und irrelevante Treffer nach oben spülen.
Morphologie: Flexion, Umlaute und Komposita
Hier liegt die eigentliche Komplexität. Das Deutsche flektiert Nomen in vier Fällen, Adjektive in drei Genera, und Verben konjugieren vielfältig. Ein einfacher Stemmer, der den Wortstamm zurückgeben soll, muss also Endungen wie -ern, -ers, -en, -er, -es, -em, -e und -n abschneiden. Dazu kommt die Umlaut-Normalisierung: ä → a, ö → o, ü → u, ß → ss. Das erlaubt es, dass eine Suche nach „Buch" auch „Bücher" findet, weil beide auf denselben Wortstamm (Stem) reduziert werden.
Noch kniffliger sind Komposita – das deutsche Spezialphänomen, beliebig lange Wörter zu bilden. „Wissensbasis", „Unterrichtsmaterial", „Schülerarbeitsblatt" sind für einen naiven Tokenizer ein einziges langes Token, das semantisch gesehen aus mehreren Konzepten besteht. Im Fork gibt es dafür eine heuristische Compound-Splitting-Funktion: Wörter ab 8 Zeichen werden an typischen Fugenmorphemen (vor allem dem Fugen-s) aufgesplittet. So wird Wissensbasis in Wissen und Basis zerlegt, und beide Teile fließen separat ins Ranking ein.
Embeddings und semantische Suche
Der semantische Teil der Suche läuft über qllama/multilingual-e5-large-instruct, das nomic-embed-text ersetzt, das primär auf Englisch trainiert wurde. Das deutschsprachige Embedding-Modell multilingual-e5 liefert deutlich bessere Ergebnisse.
Vibe Coding mit Gemini CLI / Antigravity
Ein persönlicher Bonus dieses Projekts war das Ausprobieren von Gemini CLI als Coding-Assistent. Die Kombination aus einem klar beschriebenen Problem (Deutsch-Support) und einem iterativ arbeitenden LLM-Assistenten hat gut funktioniert – besonders für die Prompt-Übersetzung und das Ausarbeiten der Stemmer-Logik. Der Ansatz zeigt, wie man ein bestehendes Open-Source-Plugin relativ schnell für die eigene Sprache adaptieren kann, ohne von Null anzufangen.
Aktueller Stand und Ausblick
Das Plugin ist lauffähig und in meinem Vault im Einsatz. Für eine erste Indexierung von ~600 Notizen muss man Geduld mitbringen – die im englischen angegebenen Zeiten (ca. 4 Stunden) werden durch die komplexeren Abläufe im Deutschen etwas verlängert. Danach werden nur geänderte Dateien neu extrahiert, was in Sekunden erledigt ist.
Offene Punkte, die ich noch angehen möchte:
- Bessere Compound-Splitting-Heuristiken für komplexere Komposita ohne Fugen-s
- Stemmer-Tests mit einem Goldstandard deutscher Wortformen
- Eventueller Upstream-Beitrag zum Original-Repo, sobald der Ansatz stabil genug ist
Der Quellcode liegt offen auf github.com/matheharry/llm-wiki-german. Wer ebenfalls einen deutschen Obsidian-Vault hat und LLM Wiki ausprobieren will, ist herzlich eingeladen, mitzumachen – Issues, PRs und Erfahrungsberichte sind willkommen.